
Multi-thread programming is essential to building high-performance applications, especially those expected to scale. This article will teach us about handling concurrency in Amazon DynamoDB with Optimistic Locking. When multiple threads try to access/modify the same record in DynamoDB, there can be data inconsistencies and conflicts. To combat this, we will implement optimistic locking to ensure your data is not lost or overridden.
This article is sponsored by AWS. Huge thanks for helping me produce more .NET on AWS content!
Problem Statement
In any application, you would need the database to be the single source of truth. Thus, it’s crucial to maintain data consistency no matter what load you are throwing at your application. I am talking about multiple threads trying to modify a single record at the same given time instance. With high-traffic applications, comes a different set of problems that you need to solve. Handling Concurrent Writes to your database is one such challenge. I faced this at work as well recently.
So, let’s say you have a table that keeps track of your inventory, with columns product ID, and stock available. Your client-side application is responsible for reducing the stock count as soon as there is a purchase. Now, imagine, if 2 client applications are connected to your server loads a particular product info, and tries to update the stock of the same product at the same instance of time. Given, that the original stock is 15.
- client #1, product #1, stock available 10 -> because client 1 sold 5 items of the product.
- client #2, product #1, stock available 14 -> because client 2 sold 1 item of the product.
Now, depending on whose request went first, the updation will happen. If client #1 hits the update button first, the sequence would be.
- update stock from 15 to 10 -> via client #1
- update stock from 10 to 14 -> via client #2
But what should be the actual stock remaining? It has to be 15 - (5 +1), which is 9. But the value on your database is 14! This leads to a huge discrepancy, and might often prove to be fatal to your business requirement. This problem becomes exponential in highly concurrent environments, where the frequency of such conflicting writes increases. This discrepancy highlights the importance of handling concurrent writes carefully to maintain data consistency.
Now imagine if these operations take place within nanoseconds. In such cases, this problem is very critical and will impact your data significantly.
I hope you understand the gist of this problem, and that you have likely come across this as well.
To handle such challenges, we have 2 major strategies.
- Optimistic Locking
- Pessimistic Locking
In this article, we will focus on the first strategy, which is Optimistic Locking, and how Amazon DynamoDB implements it.
Understanding Optimistic Locking: Handle Concurrent Database Writes
Optimistic Locking ensures that the version of the record that you are trying to update via the client is always the latest version available at the database, Amazon DynamoDB. This protects database write operations from data inconsistency and enables a smooth flow. Let us understand the algorithm for this strategy by taking the example of the inventory scenario we discussed earlier.
- To implement Optimistic Locking, systems often use Version numbers which are associated with each record. Meaning, there will be a column within the table that specifies the current version of your record.
- When the client reads an item, the version number is also loaded along with the other attributes.
- When the client wants to update this particular record, it includes the same version number in the conditional write (or delete) request.
- During the write operation, if the version number sent by the client matches the version of the record in the database, the write operation succeeds and the version is incremented.
- If there is a mismatch in the version number, the write operation would fail, and the client would have to re-fetch the latest version of the record and attempt to update the data once again. Typically, clients implement exponential backoff and retry mechanisms to handle write failures gracefully while minimizing the risk of contention and maintaining system availability.
And here is how our Inventory Management app would handle this.
- Client #1 and #2 load the latest version of the product record from the database, let’s say the version number is 2.
- The current available stock as mentioned earlier is 15.
- Client #1 makes a consumption of 5 items and updates the stock table to 15-5, which is 10. During the update request, the passed version will be 2. This matches the version available in the database, and hence the write operation succeeds. Note that the version number is also incremented during the same update call. The query would be something like ‘UPDATE inventory_table SET quantity = 10, version_number = 3 WHERE product_id = 1 AND version_number = 2;’
- After a while, Client #2 (which has stale data with version 2), makes a consumption of 1 item and updates the inventory table to 15-1, which is 14. This is so because this client has old data, which is no longer valid. Once the update request is sent via this client, the version number of the outgoing record will be 2. As you would have guessed, this is a mismatch from the version of this product in the database, which is now set to version 3. Because of this, the update operation should fail.
- Client #2 will have to be forced to reload the latest data from the database, where the newly available limit is 10 and the version is 3. Once the newer record is loaded, Client #2 will try to update the stock to 10-1, which is 9. This is the actual value we are looking for, right?! Also, the version number is incremented to 4.
This is a clear explanation of how concurrent writes can affect a system, and how we can handle it using optimistic locking.
Optimistic Locking in Amazon DynamoDB and .NET
To achieve the Optimistic Locking in DDB, the Conditional Expressions feature in Amazon DynamoDB is leveraged. DynamoDB provides support for conditional writes, where a write operation is performed only if certain conditions are met.
Let’s learn this using a simple code implementation. Open up Visual Studio and create a new .NET 8 Web API project. I named my project ‘DDB.OptimisticLocking’.
First, install the required NuGet packages to your project.
Install-Package AWSSDK.DynamoDBv2Install-Package AWSSDK.Extensions.NETCore.SetupI have already covered DynamoDB integrations in .NET in a separate article. It’s recommended that you have a basic idea about this before proceeding further. Read the article here.
Once the packages are installed, let’s create our Product class. Add a new folder named Models, and create a new class named Product.
[DynamoDBTable("products")]public class Product{ [DynamoDBHashKey("id")] public int? Id { get; set; } [DynamoDBProperty("available_stock")] public int AvailableStock { get; set; } [DynamoDBVersion] public int? Version { get; set; }}This denotes that the table name will be “products”, and the primary key/hash key will be “id”. Additionally, we will also define an extra field called Version, which is of type int.
I have already gone ahead and created a new DynamoDB table via AWS Management Console.

Let’s build the actual application now. Our application will just have 2 simple API endpoints,
- Get Product By ID
- Update Product
These endpoints will mock the internal working of our Inventory Management System. Just to keep the concept clear, I have separated these operations. Ideally, these 2 operations would take place in the same API call in the Inventory Management system. The concurrency issue that we discussed would still appear since we assume that our application gets a lot of concurrent writes.
But before that, let’s register our DynamoDB Service and Content to the ASP.NET Core DI Container. Open up Program.cs and add the following code soon after the builder object is created.
builder.Services.AddAWSService<IAmazonDynamoDB>();builder.Services.AddScoped<IDynamoDBContext, DynamoDBContext>();And here are the endpoints needed.
app.MapGet("/{id}", async (IDynamoDBContext context, int id) =>{ var product = await context.LoadAsync<Product>(id); if (product == null) return Results.NotFound(id); return Results.Ok(product);});
app.MapPut("/", async (IDynamoDBContext context, Product product) =>{ await context.SaveAsync(product); return Results.Ok();
});With that done, let’s create a dummy product in our DDB table. I have set the product id as 1 and the available stock as 15.

Build and run your .NET 8 Web API and open up the /swagger URL. Here, let’s first test out the GET endpoint. Pass 1 as the id, and run the request. If things go as expected, you will get back the data from your DynamoDB products table.

Let’s say we did a consumption of 1 item for this product. That means our total available stock has to be 14. I will use the PUT endpoint to update the available stock count to 14. Note that I have not changed the version, and it is set to null.

You can see that the update operation has returned a 200 OK status code, which means the operation has succeeded. Let’s check the data back in the AWS Management Console.

Here you can see that there is a new column named Version and it is set to 0. Now, who has changed the version from “null” to 0? It’s done internally by our .NET AWS SDK while using the IDynamoDBContext interface’s SaveAsync method.
Let’s try to do an update operation, and set the available stock count to 10. Note that we are going to keep the version as null itself! The following will be my request.
{ "id": 1, "availableStock": 10, "version": null}Once I send the update request, I will receive a 500 status code.
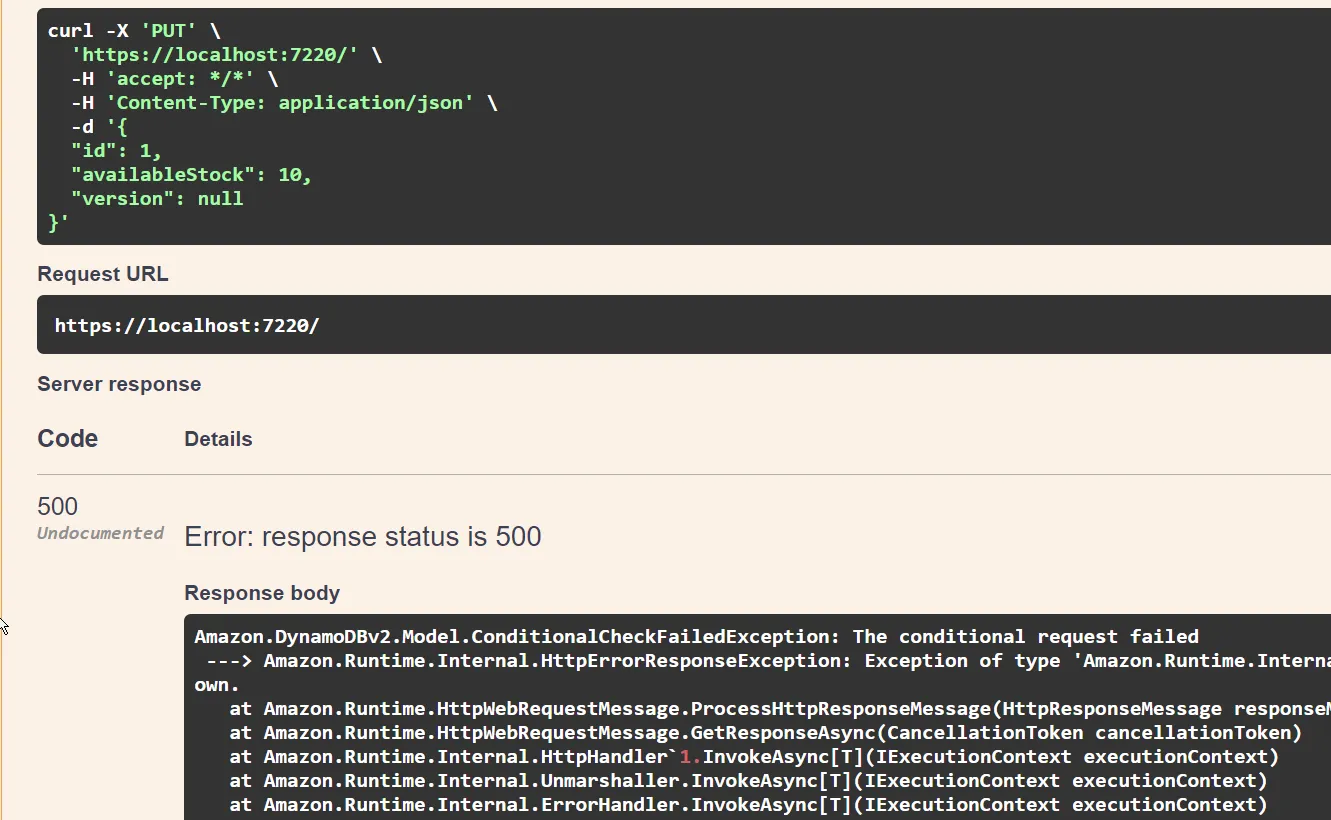
As you can see, our operation has failed with the ConditionalCheckFailed exception. Why? This is because the version we are trying to update does not match the latest version available in the database.
How do we fix this? Ideally, if the version mismatch occurs, the system should re-fetch the latest version of the record from the database, and retry the update operation. In our case, let’s execute the GET endpoint again, to get the latest version.
Here is the result.
{ "id": 1, "availableStock": 14, "version": 0}As you can see the new version is set to 0, and not null anymore.
We will use this payload to deduct the available stock. As mentioned in our use case, let’s reduce 5 items from this, that is, 14-5 = 9.

Now our API returns a 200 status code. Let’s check our DDB table now.

As you can see, the available stock is updated as expected, and the version is automatically incremented from 0 to 1. This is how easily you can handle concurrent writes to your DynamoDB table with .NET.
Skip Versioning
In cases where you want to disable Optimistic Locking, you will have to pass a config object along with the actual data while using the IDynamoDBContext interface. This ensures that the conditional check is disabled.
app.MapPut("/skip", async (IDynamoDBContext context, Product product) =>{ await context.SaveAsync(product, new DynamoDBOperationConfig() { SkipVersionCheck = true }); return Results.Ok();});Explicit Versioning with Conditional Expressions using IAmazonDynamoDB
Using the AWS DynamoDB SDK’s IDynamoDBContext object, versioning was very simple, right? As it was handled out of the box. But in cases where you need to use the IAmazonDynamoDB interface, you might have to explicitly write the code to handle conditional expressions check of versions, as well as increment it. This is also called as the Low Level APIs provided by the AWS SDK. It helps us work on a more granular level.
Although it might be a lot of code to worry about, this helps you get an idea of how the actual database query is set up, and how it will propagate.
To demonstrate and explain this, I will add another Minimal API endpoint to our ASP.NET Core Application, with a route named `/lowlevel`.
app.MapPut("/lowlevel", async (IAmazonDynamoDB ddb, Product product) =>{ var currentVersion = product.Version; product.Version++;
var request = new UpdateItemRequest { TableName = "products", Key = new Dictionary<string, AttributeValue>() { { "id", new AttributeValue { N = product.Id.ToString() } } }, UpdateExpression = "set #available_stock = :available_stock, #Version = :newVersion", ConditionExpression = "#Version = :currentVersion", ExpressionAttributeNames = new Dictionary<string, string> { { "#available_stock", "available_stock" }, { "#Version", "Version" } }, ExpressionAttributeValues = new Dictionary<string, AttributeValue> { { ":available_stock", new AttributeValue { N = product.AvailableStock.ToString() } }, { ":currentVersion", new AttributeValue { N = currentVersion.ToString() } }, { ":newVersion", new AttributeValue { N = product.Version.ToString() } } }, }; var response = await ddb.UpdateItemAsync(request); return Results.Ok();});First up, note that we are injecting IAmazonDynamoDB instance to the endpoint. We will capture the current version of the incoming update request record, which has to match the version in the database. We will also have to increment this version during the update (only if the conditional expression check has passed).
Then, we will specify the name of the table, and the key (which is ID), and pass the ID value as the key in the request.
The main things to note here are the UpdateExpression and the ConditionExpression. To the Update Expression, we will pass the fields that are to be updated, which in our case will be the available_stock and the version fields. To the ConditionExpression we will pass the attribute and value of the current version to be checked against. We will be filling these values at the ExpressionAttributeValues.
Once the request object is formed, we will pass this to the UpdateItemAsync method of the IAmazonDynamoDB interface.
Again, this should ideally generate a query similar to ‘UPDATE products SET stock_available= 10, version = 3 WHERE id = 1 AND version= 2;’. If there is a mismatch in the Version, a ConditionalExpression Failed exception will be raised as we saw earlier.
If the version matches, the stock is updated, and the current version is incremented.
To understand the request body in depth, refer to https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/LowLevelDotNetItemCRUD.html#UpdateItemLowLevelDotNet
Benefits of Optimistic Locking
The notable benefits of Optimistic Locking are:
- Data Consistency & Integrity is ensured within your system, and handles race conditions during concurrent database write operations.
- Whenever stale data is found, the system is notified. Your application is protected from stale data entering, and overwriting your actual record.
Summary
In this article, we covered an important topic in software engineering, and AmazonDB to be specific. This is a very pretty common use case when you are working at scale with multiple services. Optimistic Locking can gracefully handle such challenges. It also ensures that only the latest record is updated, and prevents any stale/invalid data from being inserted in our database.
You can find the source code of the entire implementation on this GitHub repository.
Feel free to share this article with your colleagues and network. This will help me get more eyes to this article. Thanks!




What's your Feedback?
Do let me know your thoughts around this article.